In [4]:
## Sorry, it's hard to embed gifs into Markdown chunks in a Python Notebook
from IPython.display import HTML
HTML('<img src="https://miro.medium.com/v2/resize:fit:1400/1*ubRrYAZJUlCcqg7WoKjLgQ.gif">')
Out[4]:
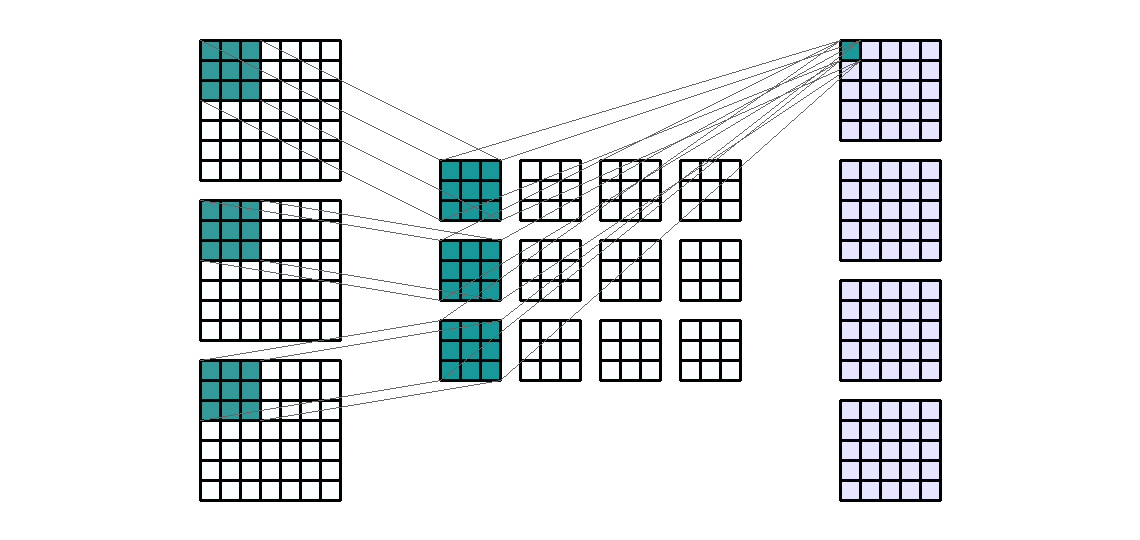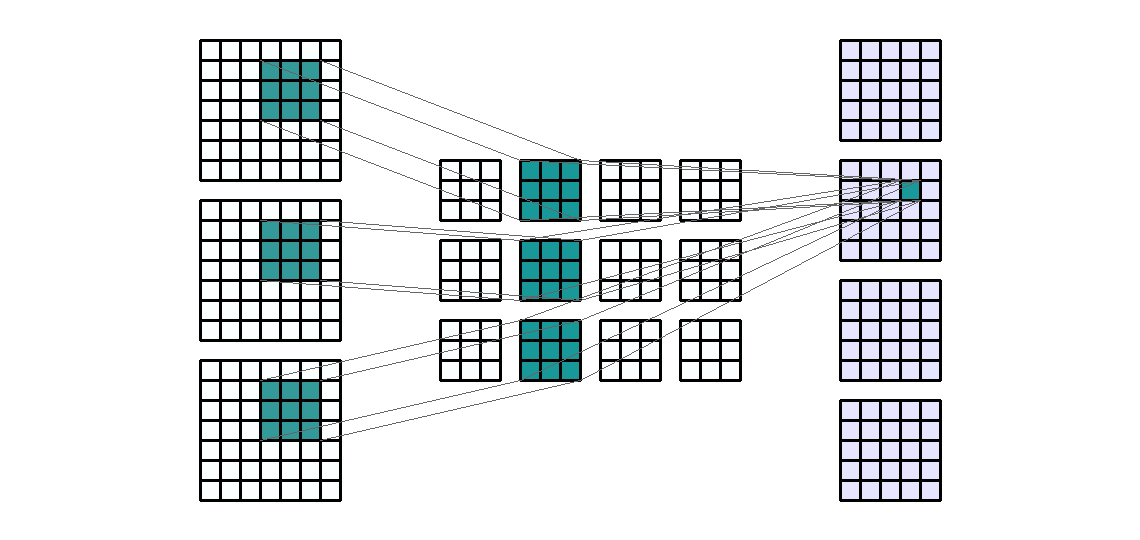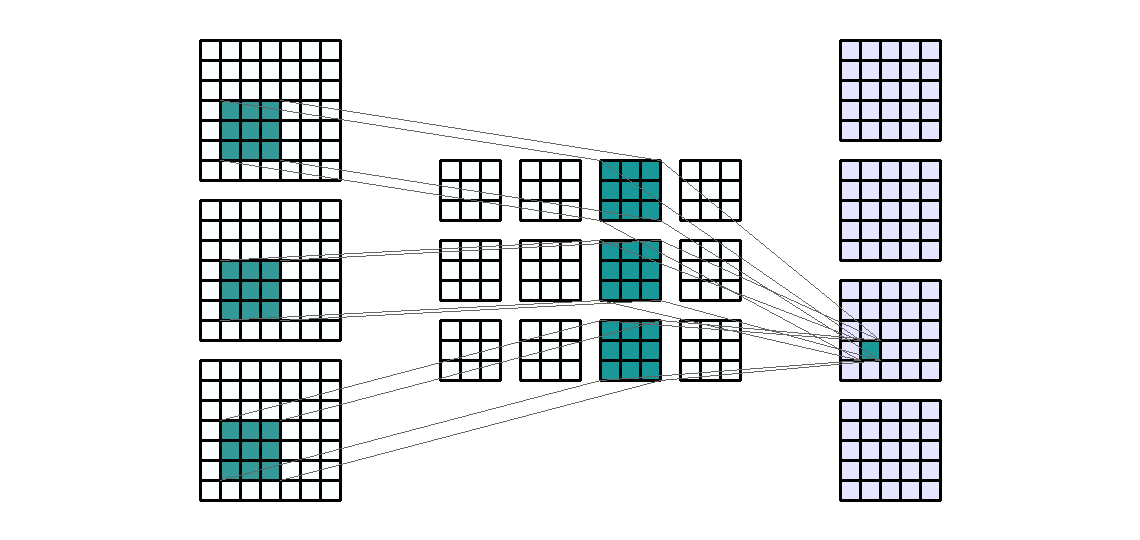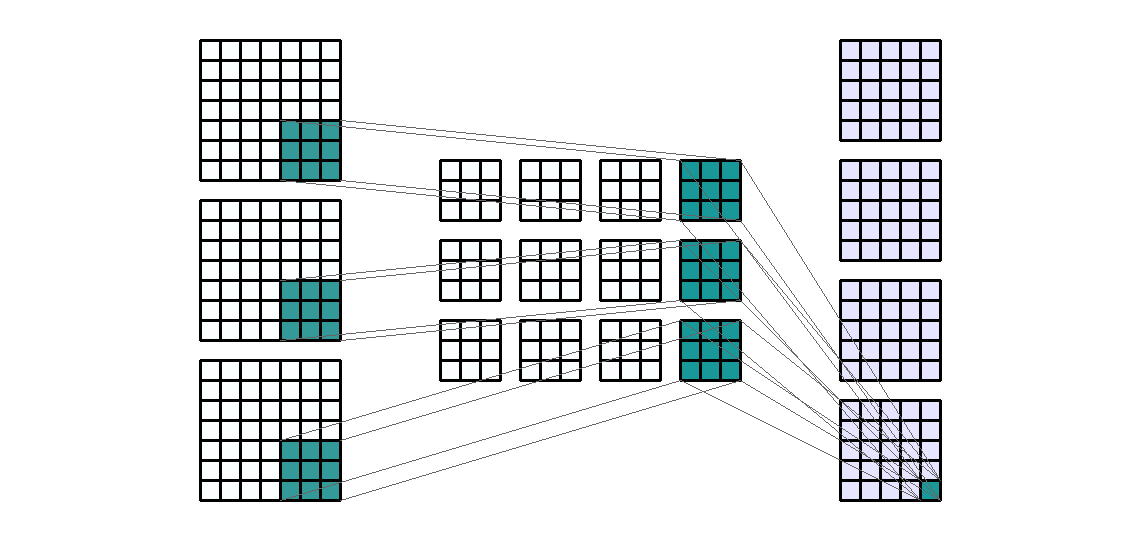
This lab covers the architecture, training, and evaluation of convolutional neural networks (CNN) using PyTorch. We'll need the following libraries:
import torch
import torchvision
import numpy as np
Our previous lab introduced the basic framework of model building and training in PyTorch. Convolutional neural networks use the same fundamental steps, but with a new type of building block, the convolutional layer, which we'll implement using Conv2d().
The example below demonstrates the four essential arguments of Conv2d() on a randomly generated tensor whose dimensions might represent a single 7x7 image with 3 color channels:
## Create random tensor to represent a 7x7 image with 3 channels
random_tensor = torch.rand(1,3,7,7)
## Use random_tensor as input into Conv2d
from torch import nn
trial_net = nn.Conv2d(in_channels=3, out_channels=4, kernel_size=3, stride=1)
trial_output = trial_net(random_tensor)
## Check output shape
print(trial_output.shape)
torch.Size([1, 4, 5, 5])
This example applied a set of 3x3 convolution filters using a stride length of 1 to our 1x3x7x7 input tensor. A few things to note:
in_channels must match the number of channels present in the input, which will be the second dimension of the input tensor if your data are appropriately formatted.out_channels determines the number of feature maps (output channels) produced by the layer. Specifying more output channels will increase the number of hidden features learned in this layer of the network.kernel_size determines the size of the filter, with kernel_size=3 indicating a 3x3 filter size. You could use a non-square kernel by supplying a tuple, such as (2,3), to this argument.Here we can see that the 1x3x7x7 input tensor was convolved into 1x4x5x5 output tensor (note that we did not use any padding).
Because our input tensor contains 3 channels and we requested 4 output channels, our network must estimate matrices of weights for 12 different 3x3 filters, as well as 4 biases (1 per output channel). Below we verify this by printing the shapes of the weights and bias tensors:
## Check weights shape
print(trial_net.weight.shape)
## Check bias shape
print(trial_net.bias.shape)
torch.Size([4, 3, 3, 3]) torch.Size([4])
To better understand the role of these weights and biases, consider the following:
[1,:,:] of trial_net.weight, act separately on the input channels to contribute, with the bias [1], to the first output channel.[2,:,:], act separately on the input channels to contribute, with the bias [2], to the second output channel.This operation is shown visually in the .gif below:
## Sorry, it's hard to embed gifs into Markdown chunks in a Python Notebook
from IPython.display import HTML
HTML('<img src="https://miro.medium.com/v2/resize:fit:1400/1*ubRrYAZJUlCcqg7WoKjLgQ.gif">')
If you're curious, printed below is the first group of weight matrices:
trial_net.weight[1,:,:]
tensor([[[ 0.1786, -0.0736, 0.1632],
[-0.1543, 0.0344, -0.0067],
[-0.0531, -0.0487, 0.1482]],
[[ 0.0546, 0.1791, -0.0844],
[-0.1099, 0.1227, 0.0527],
[ 0.1037, 0.1866, 0.1703]],
[[-0.0082, 0.1250, -0.0716],
[-0.1125, -0.1776, 0.1115],
[-0.0641, -0.0270, 0.0127]]], grad_fn=<SliceBackward0>)
Question #1: For this question, consider the Fashion MNIST training data introduced in the previous lab and a convolutional layer created using Conv2d involving 4x4 kernels, stride of 2.
Convolutional layers excel at learning spatially dependent patterns. For example, the first convolutional layer in a deep network might detect edges, curves, and color gradients. However, it is easy for convolutional layers to produce output that is substantially larger than than is desirable. For example, if the input tensor is padded and 10 convolution kernels are used to learn features from an image with a single input channel, the output tensor is now 10 times larger than the input.
Consequently, most convolutional networks use a pooling layer immediately after convolution to reduce the dimension of inputs into subsequent layers. As a demonstration, consider a randomly generated tensor of dimension [1,1,4,4]:
random_tensor = torch.rand(1,1,4,4)
print(random_tensor)
tensor([[[[0.4082, 0.5160, 0.9411, 0.7076],
[0.3695, 0.8186, 0.9490, 0.3259],
[0.5255, 0.9043, 0.4681, 0.2005],
[0.6820, 0.0663, 0.3570, 0.7139]]]])
Sliding a 2x2 pooling filter across the 4x4 slice of this tensor using a stride of 2 creates 4 distinct regions, and pooling via MaxPool2d() will keep only the maximum value in each region:
trial_pool = nn.MaxPool2d(kernel_size = 2, stride = 2)
pool_output = trial_pool(random_tensor)
print(pool_output)
tensor([[[[0.8186, 0.9490],
[0.9043, 0.7139]]]])
Similarly, we could perform average pooling, which will calculate and keep the average value in each region:
avg_pool = nn.AvgPool2d(kernel_size = 2, stride = 2)
pool_output = avg_pool(random_tensor)
print(pool_output)
tensor([[[[0.5281, 0.7309],
[0.5445, 0.4349]]]])
Whenever using a pooling layer, you should be aware of the impacts of using a stride $>1$ on an input slice with an odd number of rows and/or columns. The default pooling behavior in these situations is controlled by the argument ceil_mode.
ceil_mode = False, the pooling filter cannot go "out of bounds", so certain portions of the input tensor are not used at all. ceil_mode = True, the filter can go out of bounds so long as its left corner starts in the input (or padding, if there is any being used). Consider the example below:
## Randomly generated 1x5x5 tensor
random_tensor = torch.rand(1,1,5,5)
## Two different pooling operations
ceil_false = nn.MaxPool2d(kernel_size = 2, stride = 2, ceil_mode = False)
ceil_true = nn.MaxPool2d(kernel_size = 2, stride = 2, ceil_mode = True)
## Note the difference in output shape
print(ceil_false(random_tensor).shape)
print(ceil_true(random_tensor).shape)
torch.Size([1, 1, 2, 2]) torch.Size([1, 1, 3, 3])
Question #2
trial_output (given again below), apply ReLU activation followed by max pooling and note the output. Then, swap the order of these operations (ie: apply max pooling followed by ReLU activation). What impact does the order have on the output? ## Trial_net for Question #2
trial_net = nn.Conv2d(in_channels=3, out_channels=4, kernel_size=3, stride=1)
At any step of a convolutional neural network we might consider padding the input to ensure that features present in the edges of the input are properly handled. While not an essential step, padding is usually applied to the inputs used in a network's first convolutional layer, and sometimes to the inputs of subsequent layers.
For illustrative purposes, let's apply padding to the input tensor used in the pooling examples from the previous section:
## Randomly generated 1x5x5 tensor
random_tensor = torch.rand(1,1,5,5)
## Add padding
padding_step = nn.ZeroPad2d(padding=1)
padded_input = padding_step(random_tensor)
print(padded_input)
## See the impact
print(ceil_false(padded_input))
print(ceil_false(random_tensor))
tensor([[[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.8166, 0.6145, 0.7464, 0.4755, 0.0061, 0.0000],
[0.0000, 0.0585, 0.0078, 0.4892, 0.9638, 0.5208, 0.0000],
[0.0000, 0.9876, 0.1788, 0.5228, 0.1252, 0.1227, 0.0000],
[0.0000, 0.3907, 0.1972, 0.1292, 0.3325, 0.4888, 0.0000],
[0.0000, 0.5706, 0.8735, 0.6341, 0.6893, 0.1471, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
tensor([[[[0.8166, 0.7464, 0.4755],
[0.9876, 0.5228, 0.9638],
[0.5706, 0.8735, 0.6893]]]])
tensor([[[[0.8166, 0.9638],
[0.9876, 0.5228]]]])
You should be aware of the trade-offs involved in padding. First, the 2x2 pooling operation now is able to consider the values stored in every element of the input tensor in this example. However, the feature map is now larger than it otherwise would have been.
At this point we've covered the basics of how convolution, pooling, and padding operations are implemented in PyTorch. We're now ready to build a relatively simple convolutional neural network to use on the Fashion MNIST data (introduced in our previous lab).
Recall that this dataset contains 1000 examples (900 in the training set) of 28x28 pixel grayscale images of 10 different fashion objects.
We'll start by defining a network architecture:
from torch import nn
class my_net(nn.Module):
## Constructor commands
def __init__(self):
super(my_net, self).__init__()
## Define architecture
self.conv_stack = nn.Sequential(
nn.Conv2d(1,10,4,1),
nn.ReLU(),
nn.MaxPool2d(2,2),
nn.Conv2d(10,30,2,1),
nn.ReLU(),
nn.MaxPool2d(2,2),
nn.Flatten(),
nn.Linear(750, 250),
nn.ReLU(),
nn.Linear(250, 10)
)
## Function to generate predictions
def forward(self, x):
scores = self.conv_stack(x)
return scores
When compared to the architecture given our previous lab, you should notice that this model does not flatten the images and the sequence of functions applied in nn.Sequential() is much longer.
Question #3: Use the network architecture given above when answering the following questions. I encourage you to build your own small examples for testing purposes.
nn.Conv2d(1,10,4,1) in the first convolution operation of the network? nn.ReLU() and nn.MaxPool2d(2,2) have been applied to the output from Part A?nn.Conv2d(1,10,4,1) so long as they contain a single color channel. Does this mean that this network architecture can handle input images of any size? Briefly explain.nn.Linear(750, 250) come from? Can the network still be used on the Fashion MNIST data (in its original format) if this value is changed while every other step remains the same?nn.Linear(750, 250) be changed without requiring changes to the format of the input data? What else would have to change if this value is modified?The steps that follow are largely the same as those seen in our previous lab.
We'll begin by setting up a few of the parameters required to train our network:
## Hyperparms
epochs = 300
lrate = 0.025
bsize = 100
## For reproduction purposes
torch.manual_seed(7)
## Cost Function
cost_fn = nn.CrossEntropyLoss()
## Intialize the model
net = my_net()
## Optimizer (Stochastic Gradient Descent)
optimizer = torch.optim.SGD(net.parameters(), lr=lrate)
Now we'll prepare the MNIST data to be used with this network:
### Read flattened, processed data
import pandas as pd
fash_mnist = pd.read_csv("https://remiller1450.github.io/data/fashion_mnist_train.csv")
## Train-test split
from sklearn.model_selection import train_test_split
train_fash, test_fash = train_test_split(fash_mnist, test_size=0.1, random_state=5)
### Separate the label column (outcome)
train_y = train_fash['y']
train_X = train_fash.drop(['y'], axis=1)
test_y = test_fash['y']
test_X = test_fash.drop(['y'], axis=1)
### Convert to numpy array then reshape to 900 by 28 by 28
mnist_unflattened = train_X.to_numpy()
mnist_unflattened = mnist_unflattened.reshape(900,28,28)
## Convert to tensor
mnist_tensor = torch.from_numpy(mnist_unflattened)
train_X = torch.reshape(mnist_tensor, [900,1,28,28])
## Make DataLoader
from torch.utils.data import DataLoader, TensorDataset
y_tensor = torch.Tensor(train_y)
train_loader = DataLoader(TensorDataset(train_X.type(torch.FloatTensor),
y_tensor.type(torch.LongTensor)), batch_size=bsize)
At this point we can re-use the same training loop from the previous lab:
## Initial values for cost tracking
track_cost = np.zeros(epochs)
cur_cost = 0.0
## Loop through the data
for epoch in range(epochs):
cur_cost = 0.0
correct = 0.0
## train_loader is iterable and numbers knows the batch
for i, data in enumerate(train_loader, 0):
## The input tensor and labels tensor for the current batch
inputs, labels = data
## Clear the gradient from the previous batch
optimizer.zero_grad()
## Provide the input tensor into the network to get outputs
outputs = net(inputs)
## Calculate the cost for the current batch
## nn.Softmax is used because net outputs prediction scores and our cost function expects probabilities and labels
cost = cost_fn(nn.Softmax(dim=1)(outputs), labels)
## Calculate the gradient
cost.backward()
## Update the model parameters using the gradient
optimizer.step()
## Track the current cost (accumulating across batches)
cur_cost += cost.item()
## Store the accumulated cost at each epoch
track_cost[epoch] = cur_cost
# print(f"Epoch: {epoch} Cost: {cur_cost}") ## Uncomment this if you want printed updates
We can plot the cost by training epoch to verify that the model has converged:
import matplotlib.pyplot as plt
plt.plot(np.linspace(0, epochs, epochs), track_cost)
plt.show()

And since this workflow is no longer new, let's jump straight to evaluating the network's accuracy on the test data:
## Make test outcomes into a tensor
test_y_tensor = torch.Tensor(test_y.to_numpy())
### Convert to numpy array then reshape
test_unflattened = test_X.to_numpy().reshape(len(test_y),1,28,28)
## Convert test images into a tensor
test_tensor = torch.from_numpy(test_unflattened)
## Combine X and y tensors into a TensorDataset and DataLoader
test_loader = DataLoader(TensorDataset(test_tensor.type(torch.FloatTensor),
test_y_tensor.type(torch.LongTensor)), batch_size=bsize)
## Repeat evaluation loop suing the test data
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(correct/total)
0.78
Our convolutional neural network is able to achieve a modestly higher classification accuracy (under ideal circumstances) than our previous neural network. However, this model includes many more parameters, which makes it much more difficult to train.
Additionally, you should be aware that neural networks are overparameterized models (in statistical terms), so they will not learn the same weights if you repeatedly train them using the same training data with different random initializations of the weights and biases. Nevertheless, with a little bit of trial and error it's possible to arrive at a network that achieves a cost $\leq 14$ (measured in terms of how it was calculated in our loop), and a test set accuracy of around 80%.
It's also worth pointing out that it is common in neural network training to need to "restart" a few times to get a favorable set of randomly generated weights that allows the model to gain traction and begin to learn patterns in the data.
Convolutional neural networks are robust to the precise positions of hidden features in an image, so a common strategy used during network training is data augmentation, or the intentional alteration of training images in ways that preserve their meaning in order to provide the network with a larger and more diverse set of training examples.
For example, we could augment the Fashion MNIST data by randomly flipping each image horizontally (since a shoe is still a shoe regardless of whether the toe is pointed to the left or to the right). We might also think that adding a little "fuzz" or blurring to some of the images could provide additional variety without fundamental altering what each image means.
Below we define a set of data augmentation transformations that we can later use in our training loop:
## Compose our set of data augmentation transformations
from torchvision import transforms
data_transforms = transforms.Compose([
transforms.GaussianBlur(kernel_size=(5,5), sigma=(0.1, 5)),
transforms.RandomHorizontalFlip()
])
Note that the kernel_size argument seen here defines the dimensions of the Gaussian kernel, and the two values used in the sigma argument represent the min and max of the range from which the standard deviation of the random noise will randomly be sampled from for each kernel. This link provides a more detailed (and relatively non-technical) explanation of Gaussian blurring.
Now let's utilize these data augmentation transformations on each batch of images during our training loop:
## Re-run the training loop, notice the new data_transforms() command
track_cost = np.zeros(epochs)
cur_cost = 0.0
for epoch in range(epochs):
cur_cost = 0.0
correct = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
## Transform the input data using our data augmentation strategies
inputs = data_transforms(inputs)
## Same as before
optimizer.zero_grad()
outputs = net(inputs)
cost = cost_fn(nn.Softmax(dim=1)(outputs), labels)
cost.backward()
optimizer.step()
cur_cost += cost.item()
## Store the accumulated cost at each epoch
track_cost[epoch] = cur_cost
# print(f"Epoch: {epoch} Cost: {cur_cost}") ## Uncomment this if you want printed updates
plt.plot(np.linspace(0, epochs, epochs), track_cost)
plt.show()

Based upon the results shown in this graph, we can see that the extra variety provided by these augmented training examples appears to help the model learn more consistently.
For additional information and examples of various other types of data augmentation methods this page PyTorch documentation provides details.
Question #4: For this question you will revisit the cats vs. dogs image data stored in the zipped folder at this link. Recall that this folder includes 50 images of cats and 100 images of dogs (chihuahua breed). In our previous work with these data, it was immensely challenging to get a neural network to learn anything meaningful. This time, using the new methods introduced in this lab, we'll aim to build a neural network that at least learns something from the images.
random_state=5. Next, reorganize the dimensions of the image tensor to follow the conventional format of (N images, C color channels, w pixels, h pixels).torch.manual_seed(3) I was able to achieve 73.2% classification accuracy on the training data (which is better than the 66% you'd expect from random guessing), as well as 81.5% classification accuracy on the test data (which might have involved some luck).